机器学习课程——糖尿病预测
具体流程为
数据预处理
模型构建
实验结果
1、数据预处理
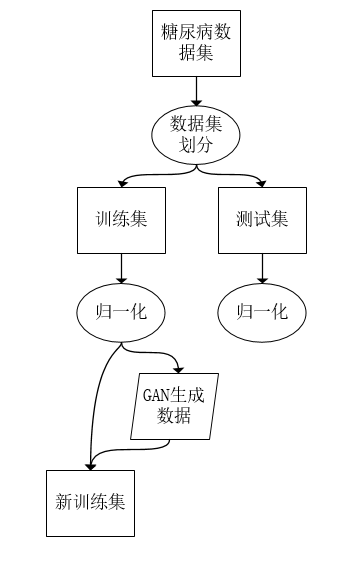
对数据集进行划分和归一化等常规操作后观察到两种类别存在不平衡的问题,这会对模型的训练产生偏差。为了解决该问题使用生成对抗网络(GAN)进行训练并产生新的数据加入到训练数据集中以平衡两种类别。生成对抗网络(GAN)能够学习到原有数据集的分布情况,产生的数据能与原有数据保持相同的分布即新的数据可以在一定程度(GAN的设计与训练的好坏)上认为是真实的样本。
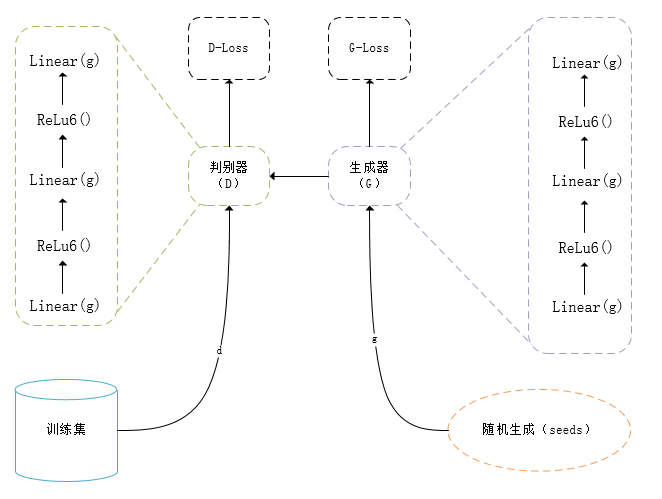
2、模型构建
1、分别使用神经网络(NN)、随机树(ET)、逻辑回归(Logistic)、支持向量机(SVM)、GradientBoosting(gdbt)、AdaBoost、XGBoost、LightGBM、CatBoost等模型对数据集进行训练和测试。
2、尝试使用单模型进行融合,使用融合后的模型对数据进行训练和测试。模型融合使用多数投票分类器。
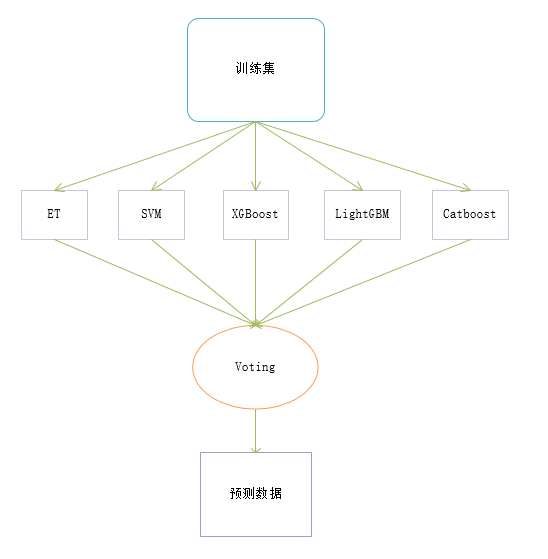
融合
3、实验结果
| 模型融合 | 神经网络 | CatBoost | |
|---|---|---|---|
| accuracy | 83.1% | 82.1% | 82.4% |
| F1-score | 72.0% | 70.2% | 70.6% |
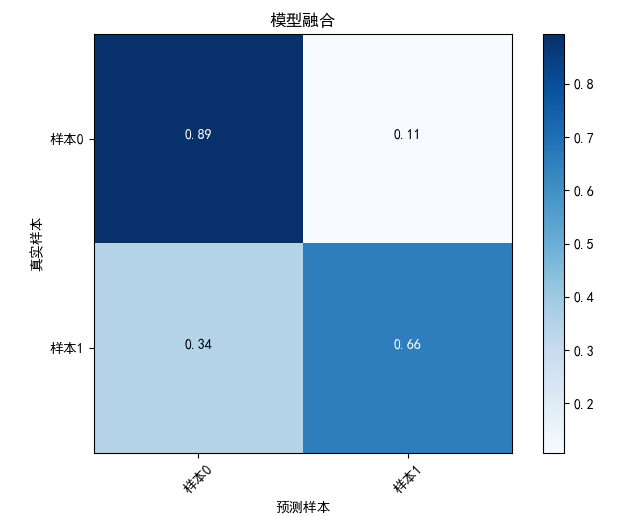
模型融合
.png)
模型融合(GAN)